 Articles
ArticlesSynchronization
StrataCode includes a data-sync library that expands upon RPC, adding a higher-level way to build client/server applications. The protocol is modelled from annotations attached to shared layers of code. The data-sync library tracks changes made to shared objects, and sends then across the wire in both ways in batches. These batches can also include method calls made. If a network connection fails, the sync will be retried when it reconnects. Because sync works both ways, it supports real-time updates from the server.
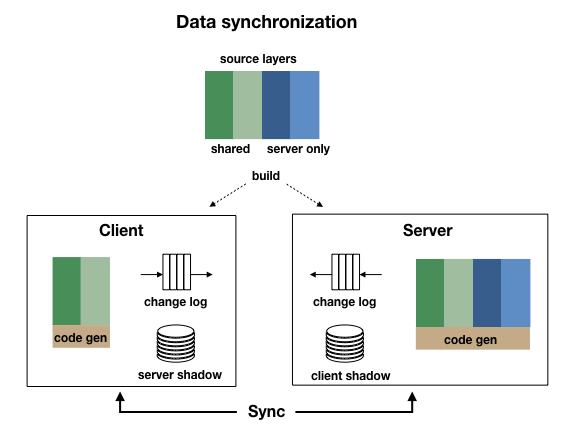
Layers are a natural way to model the overlapping code and data involved in client/server. Shared layers runs on both client and server, others on the server only. The code processor generates two versions of each of the shared classes, one for each side along with metadata for performance and security. Shared layers can enable sync by default for all types in that layer, or it can be turned on at the class or property level.
How it works
At code-generation time, an addSyncInst call is added to the class init code along with runtime metadata derived from the annotations. Synchronized properties are made bindable with getX/setX methods and change events.
At runtime, the system tracks all new instances created, destroyed and property changes. Changes are queued to be sent to the remote side on the next sync. When the sync request is successful, a shadow copy of the remote side is updated. Only changed values are sent across the wire.
The sync operation list can also include remote method calls and responses. This makes for more powerful RPC because synchronized objects can be passed by reference, not value and the return from a method call can return side-effects, not just the return value.
A call to a remote method is detected at build time when code in one process tries to call a method defined in a different one. Synchronous remote method calls are replaced transparently in the generated code. Async remote method calls generate an error unless they are made from a data binding expression.
Using remote methods in data binding expressions is particularly useful because it makes it easy to run code in either one process or in a client/server environment, just by changing the configuration.
Sync and scopes
Components in StrataCode are organized based on their lifecycle, using scopes. The web framework supports the scopes global, application, session, app-session, window, or request. Additional scopes can be created for multi-tenant data, or another class of information that's available within a well-defined current context.
When scopes are nested, events propagate from the lower-level scope to the higher level one providing easy, real-time collaboration. The system performs necessary locking to prevent two conflicting threads from running at the same time using read/write locks. So if you have a shared object between two scopes, changes made by one are queued and delivered to the other on the next thread that runs in the destination scope.
One way this is particularly useful even for non-collaborative applications is in writing test scripts. The command line/test script can invoke methods to be called on a specific browser window. This allows it to easily script complex interactions, even those involving multiple participants.
Another way scopes are helpful is providing configurable ways of managing state. For example, to preserve information on a page when the user refreshes a page use app-session scope. To reset the page information use window scope.
Reliability and responsiveness
Using synchronization to manage state has a nice benefit for scaling web applications. There are a variety of scopes to cache data as needed for different purposes. These caches reduce the load on the database, and reduce the latency.
Recovering state on failure
Synchronization works best with sticky sessions, where one client's requests return to the same server each time. This architecture improves the effectiveness of caching and makes systems scale better.
But when the server hosting a session fails, it's important to preserve the user's login state, and application context. Most web servers today do support replicating session state on another server, but data-sync provides another option. It stores that information on the client instead. When the client sees that it's session is gone, it re-sends this reset state to the server in addition to any requests it needs to perform.
Stateless when needed
For stateless requests, use request scope where sync will send all state on each request.
Examples
See these examples of applications built using synchronization: UnitConverter, TodoList, Sitebuilder, and Program Editor.
Documentation
Read more in the doc
 StrataCode
© 2020 Jeffrey Vroom
StrataCode
© 2020 Jeffrey Vroom